
안녕하세요, 피처링 엔진 팀 DA 파트의 Patty입니다 🙂
오늘은 피처링에서 활용되고 있는 감정분석 모델과 감정분석이 비즈니스적으로 어떻게 활용되고 있는지에 대한 구체적인 사례를 공유해보고자 합니다. 최근 많은 브랜드가 고객의 소리(VOC)에 집중하고 있는데요. 고객의 소리에 귀를 기울임으로써 그들의 니즈를 더 잘 이해하고 충족시킬 수 있으며, 더 나아가 제품과 서비스를 올바른 방향으로 개선할 수 있습니다.
소셜미디어를 통한 교류가 활발해지고 있는 만큼 사람들은 그 어느 때보다 소셜미디어를 통해 제품과 서비스에 대한 자신의 경험과 감정을 자주 공유하고 있습니다. 감정 분석은 이러한 모든 표현과 경험을 텍스트 형태로 마이닝 하여 브랜드 모니터링, 소셜 미디어 모니터링, 시장조사 등 비즈니스 분석이 요구되는 다양한 영역에서 활용되어 의미 있는 사용자 인사이트를 제공하고 있습니다.
감성분석이 무엇인가요?
감성분석 (sentiment-analysis)이란 “특정 텍스트가 긍정적인지, 부정적인지, 혹은 중립적인지 확인하는 프로세스”입니다.
KOTE(Korean Online That-GUgul Emotions) 모델을 통해 텍스트를 44가지 감정값으로 분류 후, 긍정/부정/중립으로 나누어볼 수 있는데요. KOTE 모델은 서울대학교 심리학과 연구실에서 개발한 감성분석 모델로 다양한 국내 온라인 플랫폼 (뉴스, 온라인 커뮤니티, 소셜미디어 등)에서 수집한 50,000개의 댓글 데이터를 대상으로 훈련했기에 인스타그램, 유튜브 등의 국내 SNS 콘텐츠 분석에 특히 적합한 모델입니다. 실제 온라인 사용자들의 데이터로 훈련했기 때문에 다른 모델들에 비해 최근 유행어나 신조어, 한국어 고유의 특성들과 정교한 감정들이 더 잘 반영되었을 거라고 가정합니다.
모델이 정의한 44가지 감정값들은 아래와 같습니다.

44가지 값들은 또다시 “부정”, “중립”, “긍정”의 3가지의 대분류로 나눠 볼 수 있는데요. 이렇게 감정값들을 사용자 기준에 따라 분류해 놓으면, 콘텐츠나 키워드 단위로 감성을 파악하는 데에 도움이 됩니다. 가령 최근에 올린 인스타그램 포스트 반응이 긍정적인지 부정적인지 알아보고 싶다면, 포스트에 달린 댓글 텍스트들을 하나씩 분석해 각각 “부정”, “중립”, “긍정”로 분류한 후, 해당 포스트의 “부정”, “중립”, “긍정” 댓글 비율을 산출해 볼 수 있습니다.
모델 활용
모델을 파이썬에서 불러와 활용할 수 있습니다.
https://github.com/searle-j/KOTE
위 github페이지에서 데이터셋을 내려받아 모델을 불러옵니다. 모델은 논문에서 사용된 정식 버전인 pytorch lightning와 간소화버전인 huggingface Trainer가 있습니다.
이번 예시에서는 편리성을 위해 huggingface Trainer를 활용해보겠습니다.
1) 데이터셋 불러오기
huggingface datasets으로 데이터셋 내려받습니다.

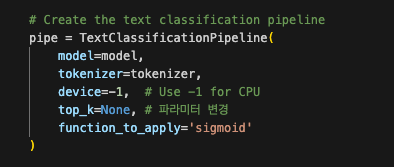
2) 모델 불러오기 및 pipeline 정의
huggingface Trainer 모델을 불러오고 pipeline을 정의합니다.

3) 모델에 텍스트 입력하여 결과 출력하기
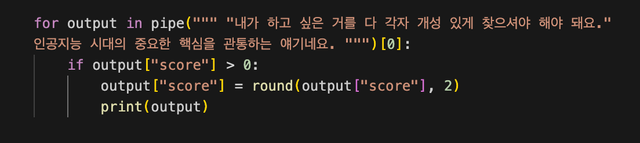
모델을 불러오고나면 이제 원하는 텍스트를 입력하여 감성분석을 시도 할 수 있습니다.
-
for ouput in pipe(“““ “““)
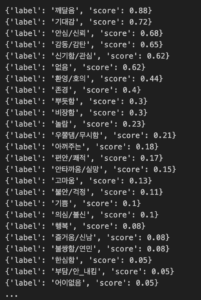
따옴표 안에 텍스트를 입력하면, sentiment score가 가장 높은 감성부터 차례대로 결과들이 나열되는데요. 0에서 1까지의 점수로 환산한 sentiment score는 값이 클수록 해당 감성 분류에 대한 신뢰도가 높다는 것을 의미합니다. 위 예시에서는 sentiment score 0 이상의 모든 감성을 출력하도록 입력하였지만, sentiment score 기준점이 있는 경우라면 기준 score 이상의 값들만 출력하도록 입력할 수도 있습니다.
하나의 텍스트에 대하여 여러 가지 감성값들이 출력되기 때문에 분석 과정에서 텍스트 분류 기준을 명확히 하는 것도 중요합니다. 텍스트를 TOP1의 감성 하나로만 분류할 수도 있고, 기준 score 이상의 감성값들을 모두 고려하여 하나의 텍스트를 여러 가지 감성으로 분류할 수도 있습니다.
위 예시에서는 [챗GPT] 이보다 쉬운 설명은 없다 ‘챗GPT’ (홍진경, 안될 과학홍진경,안될과학, 궤도, eng) 영상 댓글 중 하나를 가지고 모델을 테스트 해보았는데요. 언뜻 보기에는 “~라는 이야기네”라는 어떠한 사실을 전달하는 중립적인 의미로 볼 수 있지만, 실제로는 작성자가 영상 특정 부분을 통해 인사이트를 얻어냈다는 의미로 분석되어 “깨달음”이라는 값으로 분류되었습니다. 이처럼 KOTE 모델은 텍스트의 전체적인 문맥을 이해함으로써 작성자의 의도와 문장에 들어가있는 세밀한 감정(반어적인 표현 등)까지 세밀하게 분석하여, 긍정/부정 분류를 보다 더 정확하게 할 수 있다는 장점이 있습니다.
비즈니스 사례
감성분석은 여러 비즈니스 케이스들을 해결하는데에 활용되기도 하는데요. 한가지 예시로 피처링과 C기업과 함께 진행한 비즈니스 사례를 살펴보고자합니다.
1) 니즈
C기업측에서는 소셜미디어 여론 및 오너 리스크 모니터링을 하고자하는 니즈가 있었고, 더 나아가 기업관련 긍정/부정 콘텐츠를 지속적으로 모니터링 하고자하는 니즈가 있었습니다.
2) 분석 과정
i) 콘텐츠 정의 및 데이터 수집
104가지 키워드를 선정하여 관련 콘텐츠를 정의했습니다. 104가지 키워드 리스트내에는 오너관련 키워드와 기업계열사 및 브랜드 관련 키워드들이 포함되었습니다.
소셜미디어 플랫폼을 크게 인스타그램, 유튜브, 틱톡, 트위터 네가지로 한정하고, 약 한달간 매일 일정한 시간에 데이터를 수집하였습니다.
ii) 분석 대상
경우에 따라 콘텐츠(포스트) 본문 또는 댓글을 분석할 수 있습니다. 인스타그램, 유튜브는 유저 수가 상대적으로 많은 플랫폼인만큼 콘텐츠에 대한 유저들의 반응이 포스트의 성향을 판단하는데에 중요한 요소인 반면, 틱톡,트위터의 경우는 본문 텍스트 자체가 포스트 성향을 직접적으로 반영한다고 판단하였기에 이점을 고려하였습니다. 유튜브, 인스타그램은 댓글 텍스트를, 틱톡, 트위터의 경우는 본문 텍스트를 기준으로 감성분류를 진행했습니다.
iii) 긍부정 분류 기준
텍스트를 분석하여 sentiment score가 가장 높은 한가지 감정값을 기준으로 분류했습니다. 유튜브와 인스타그램은 댓글의 긍정,부정 비율을 산출하여 콘텐츠 성향을 파악하였고, 틱톡과 트위터의 경우 각 콘텐츠마다 긍정,중립,부정으로 분류하여 콘텐츠 성향을 파악하였습니다.
3) 결과물
데이터를 수집하고 분석한 결과를 바탕으로 대시보드 시안을 제작하여 공유했습니다. 대시보드 시안에는 키워드별 언급량 및 긍정, 부정댓글 현황, 주요 이슈 키워드에 대한 긍정/부정 분류, 긍정 부정 비율을 반영한 콘텐츠 캘린더뷰 등이 포함되었습니다.
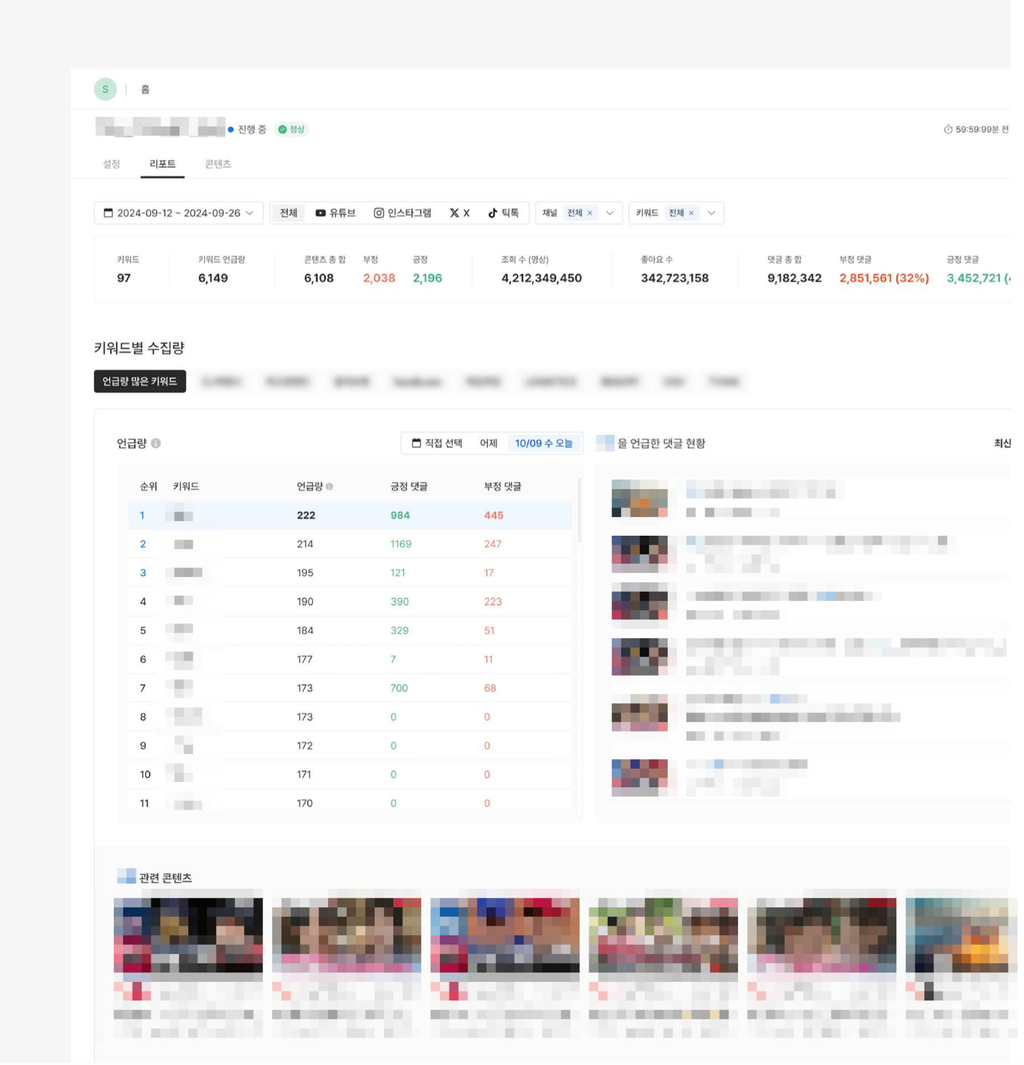
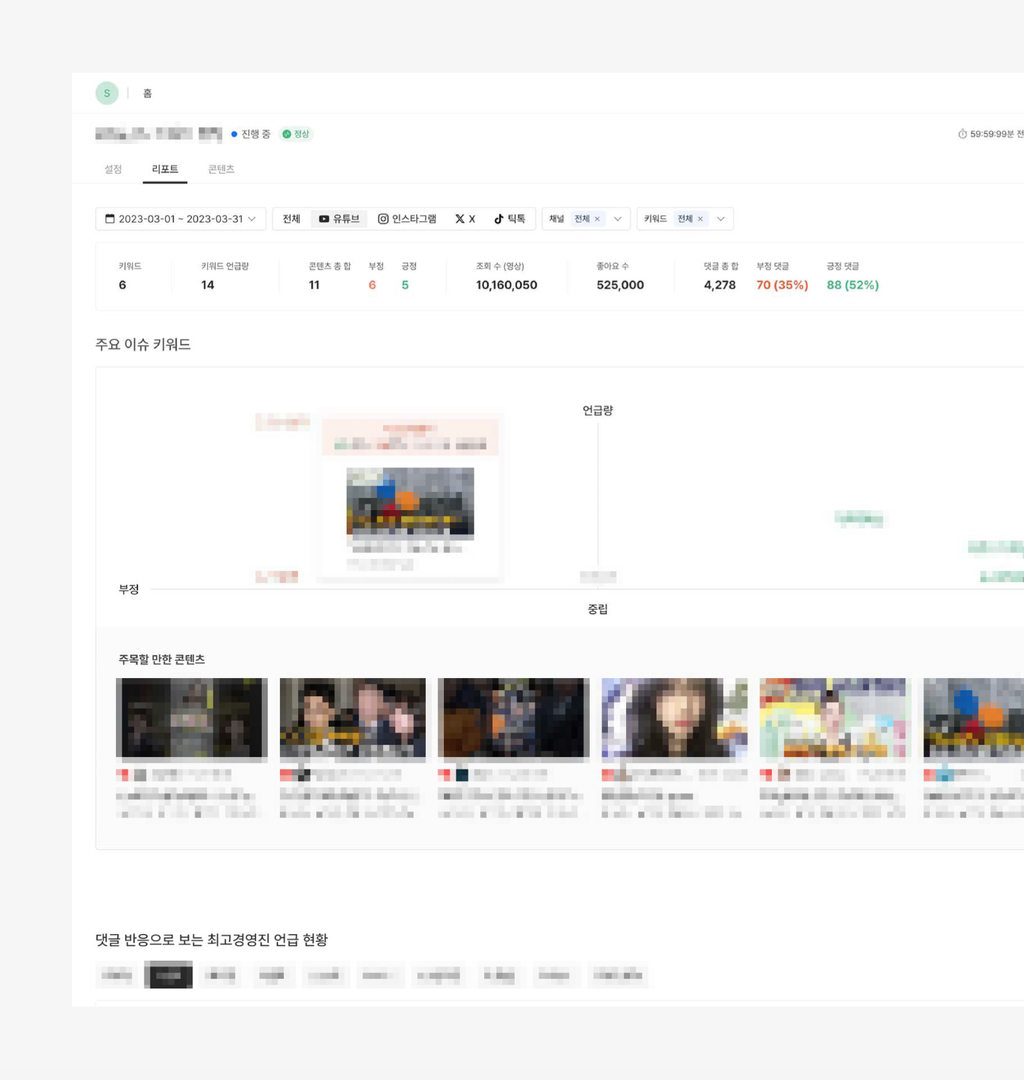
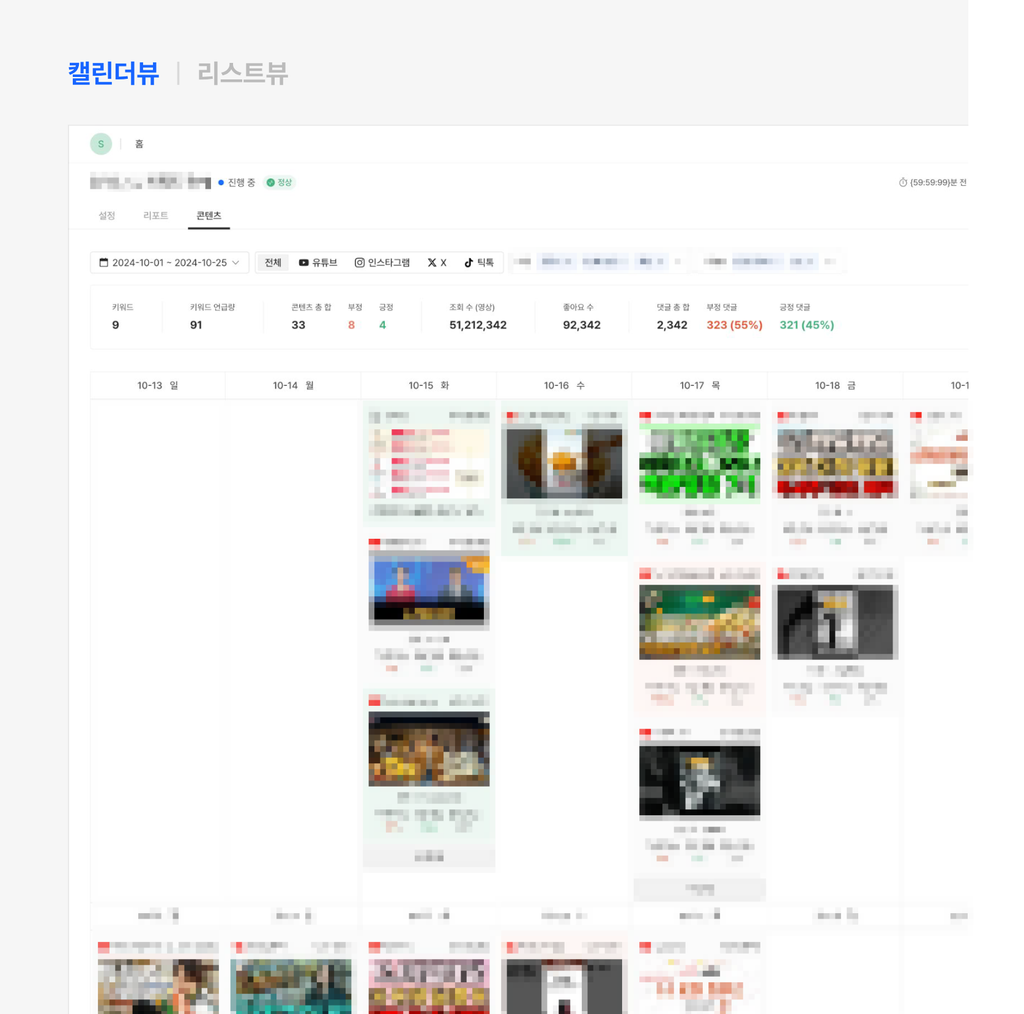
출처
https://www.ibm.com/kr-ko/topics/sentiment-analysis
https://dontn.tistory.com/entry/User-Guide-for-KOTE-Korean-Online-Comments-Emotions-Dataset
https://brunch.co.kr/@hrkaylee/11
https://ko.shaip.com/blog/the-what-why-and-how-of-sentiment-analysis/