
안녕하세요, 피처링 엔진 팀의 Harry입니다.
최근 피처링 엔진 팀에서는 수많은 SNS 데이터를 수집하고, 이를 효율적으로 가공하는 데이터 파이프라인을 구축했습니다.
이번 글에서는 DuckDB를 활용해 SNS Raw Data를 사용하기 쉽도록 정제(Cleansing)하고 적재하는 과정을 공유하려고 합니다.
이런 고민이 있는 분들께 추천드립니다!
-
DuckDB에 대해 궁금하신 분
-
데이터 분석에서 Pandas가 느려 대안을 찾고 계신 분
-
데이터 크기가 분산 처리 엔진을 사용할 만큼 크지 않아, 싱글 머신 솔루션을 찾고 계신 분
Data Cleansing이란?
Data Cleansing(또는 Data Cleaning)은 데이터를 더 정확하고 신뢰할 수 있도록 정리하고 오류를 수정하는 과정을 의미합니다. 피처링에서의 Data Cleansing은 수집한 모든 인플루언서의 Raw Data를, 필요로 하는 모든 곳에서 사용하기 편리한 형태로 가공하는 작업입니다.
기존 방식의 한계
현재 피처링에서는 하루에 약 10만 명 이상의 인플루언서 데이터(계정, 콘텐츠)를 수집, 가공, 분석하고 있습니다. 회사의 성장과 함께 요구하는 데이터 처리 요구량도 기하급수적으로 증가하고 있지만, 기존 Data Cleansing 방식은 단순히 Python Script로 처리하는 방식이었기에 대규모 데이터셋을 다루기에는 적합하지 않았습니다. 이러한 한계를 해결하기 위해 효율적인 데이터 파이프라인을 새롭게 구축하게 되었습니다.
신규 데이터 파이프라인 구축 시 고려사항
효율적인 Data Cleansing 파이프라인 구축을 위해 팀 내부적으로 아래와 같은 포인트를 고려했습니다.
-
OLAP 워크로드에 적합한가 : SNS Raw Data의 구조가 워낙 복잡하기 때문에 이를 정제하는 과정에서도 고도의 데이터 처리 능력이 필요합니다.
-
뛰어난 성능(리소스, 빠른 Cleansing 속도 등) : 데이터 수집량이 점점 증가하고 있어, 대규모 데이터를 빠르게 처리할 수 있는 Cleansing 속도가 중요합니다.
-
관리 및 운영의 효율성 : 데이터를 주기적으로 Cleansing하는 작업의 자동화와, 오류 발생 시 빠르게 대응할 수 있는 모니터링 시스템 구축이 필요했습니다.
-
빠르게 구축이 가능한가 : 피처링 솔루션의 일본 버전 런칭 일정에 맞추어 짧은 시간 내에 효율적인 파이프라인 구축이 요구되었습니다.
DuckDB란 무엇인가요?
팀에서는 처음에 Python 기반 데이터 분석 라이브러리인 Pandas와 더 높은 성능을 제공하는 Polars를 후보로 고려했습니다.
Pandas는 Python 사용자에게 익숙하다는 장점이 있지만 대규모 데이터셋에서 성능이 저하되는 단점이 존재하고, Polars의 경우 Columnar 데이터 프레임 라이브러리로 Pandas와 유사한 문법으로 친숙하면서도 매우 빠르게 대규모 데이터셋 처리를 할 수 있지만 클라우드 데이터(S3 등)에 대한 직접적인 지원 부족하고 SQL 기반 워크로드와 호환성이 부족하다는 단점이 존재합니다. 이러한 단점들 때문에 고민하던 와중 팀에서 Data Cleansing에 사용하기로 결정한건 바로 DuckDB입니다.
DuckDB는 고성능의 Columnar SQL 분석 데이터베이스 관리 시스템(DBMS)입니다. 주로 OLAP 워크로드에 최적화되어 있으며, 로컬 환경과 임베디드 방식으로 동작하도록 설계되었습니다. SQLite와 유사한 방식으로 동작하지만, 데이터 분석 작업에 초점을 맞추고 있습니다.
DuckDB의 장점
-
매우 간단하게 사용 : SQLite처럼 간단하게 설치 및 실행이 가능합니다.
-
강력한 성능을 보유 : Columnar 처리로 집계 및 분석 작업에서 높은 성능을 제공하며 OLAP 워크로드에 적합합니다.
-
다양한 파일 포맷과의 호환성 : Parquet, CSV, JSON 등 다양한 데이터 파일 포맷을 지원합니다.
-
Python, R과의 통합
-
AWS S3와 같은 클라우드 스토리지의 데이터를 직접 쿼리가 가능 : Parquet, Arrow와 같은 파일 포맷을 직접 쿼리 가능하며 클라우드 기반 대규모 데이터 처리에 매우 적합하다
특히 DuckDB의 가장 큰 장점은 별도의 서버 프로세스를 필요로 하지 않고, 애플리케이션에 임베디드 형태로 동작하기 때문에 가벼우면서도 확실한 성능이라고 할 수 있습니다.
https://duckdblabs.github.io/db-benchmark/
글에서 GroupBy, JOIN 성능 결과를 확인할 수 있습니다. 다른 도구들보다 뛰어난 성능을 보이며, Polars보다도 뛰어난 성능을 제공합니다.
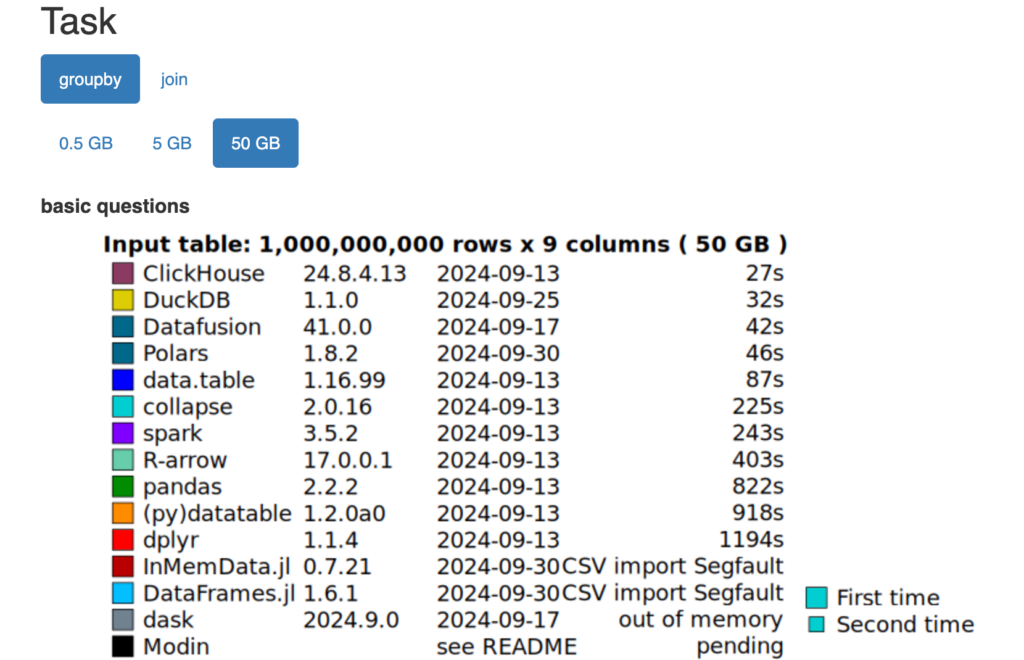
특히
https://duckdb.org/2024/06/26/benchmarks-over-time.html
글에서 보면 최근 3년동안 DuckDB가 3~25배 빨라지고, 10배 많은 데이터를 분석할 수 있게 되었다는 내용이 있는데 DuckDB가 최근에 많은 성능 향상이 있었다는 점이 주목할만한 점입니다.
DuckDB 적용 과정
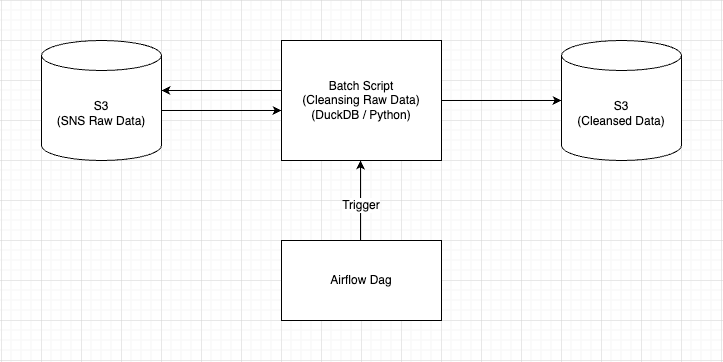
위 이미지는 SNS Raw Data를 Cleansing하는 과정을 간단하게 Diagram으로 표현한 것입니다.
Diagram에서 볼 수 있듯이 Cleansing 과정은 크게 세 가지로 나뉩니다.
#1 Airflow Dag를 통해 Cleansing Batch Script 실행
S3에 Raw Data가 시간 단위 Partition으로 적재되기 때문에 Cleansing 작업 역시 시간 단위로 진행되어야 합니다. 이를 위해 매 시간 5분마다 Airflow DAG를 통해 지정된 Batch Script가 동작하도록 설정하였습니다.
#2 DuckDB에서 S3에 접근하여 Raw Data 조회
1. S3 접근 자격 증명 (CREDENTIAL_CHAIN)
보통 Python에서 S3에 접근하려면 boto3를 사용해야 하지만, DuckDB를 활용할 경우 이를 별도로 설정할 필요가 없습니다. DuckDB는 S3에 접근할 때 CREDENTIAL_CHAIN이라는 체계를 사용하여 자격 증명을 확인합니다.
CREDENTIAL_CHAIN은 자격 증명을 확인하는 체계로, 다음과 같은 우선순위에 따라 인증 정보를 검색합니다.
-
DuckDB 내에서 명시적으로 설정된 자격 증명 : SET s3_access_key_id 및 SET s3_secret_access_key 명령어로 설정된 값
-
Environment Variables : AWS_ACCESS_KEY_ID와 AWS_SECRET_ACCESS_KEY가 환경 변수로 설정된 경우
-
AWS Credentials File : 일반적으로 ~/.aws/credentials에 저장된 자격 증명 파일로 AWS CLI에서 설정된 프로필을 기반으로 자격 증명을 읽습니다.
-
IAM Role : DuckDB가 AWS EC2 인스턴스에서 실행 중이고, EC2에 IAM 역할이 연결된 경우, EC2 메타데이터 서비스를 통해 자격 증명을 자동으로 검색합니다.
피처링의 경우 Python Script가 실행되는 환경이 EC2 인스턴스이며, EC2 인스턴스에 IAM 역할이 연결되어 있기 때문에 CREDENTIAL_CHAIN을 통해 초기 설정을 해주면 별도의 추가 설정 없이 AWS S3에 접근이 가능하도록 구현되어 있습니다.
아래 예시 코드처럼 DuckDB에 연결 후 CREDENTIAL_CHAIN 설정을 해주면 끝.
def create_duckdb_connection_for_s3():
conn = duckdb.connect()
conn.execute(
"""
CREATE SECRET secret (
TYPE S3,
PROVIDER CREDENTIAL_CHAIN
);
"""
)2. 멱등성을 위한 Overwrite
Cleansing 작업을 진행하다 보면 Raw Data에 노이즈가 포함되어 실패하거나, 특정 데이터를 다시 Cleansing해야 하는 상황이 발생할 수 있습니다. 이러한 경우, 같은 시간 단위 Partition에 여러 개의 파일이 생성될 수 있으며, 이로 인해 잘못 저장된 파일이 함께 처리되어 멱등성을 보장하기 어려워질 수 있습니다. 따라서 이전에 저장된 파일을 Delete하거나 Overwrite하는 과정이 필요합니다.
하지만 DuckDB는 S3에 저장된 파일을 직접 Delete하거나 Overwrite하는 기능을 제공하지 않는다고 하는데 DuckDB가 S3에 저장하는 기능은 제공하면서도, 파일 관리 작업은 포함하지 않는 이유는 무엇일까요?
DuckDB가 S3에 데이터를 저장하는 원리
일단 DuckDB가 S3에 데이터를 저장하는 원리부터 살펴봐야 합니다. DuckDB는 S3 버킷을 대상으로 파일을 저장할 때 객체 스토리지 API를 통해 동작합니다. 여기서 객체 스토리지 API란, 클라이언트와 객체 스토리지 서비스(Amazon S3, Google Cloud Storage 등) 간의 데이터 조작을 가능하게 하는 인터페이스를 뜻하는데 주요 작업은 다음과 같습니다.
-
데이터 쓰기(Upload)
-
데이터 읽기(Download)
-
데이터 삭제(Delete)
-
메타데이터 관리
-
버킷 및 객체 관리
DuckDB의 COPY 명령에서 TO 옵션을 사용하면 DuckDB가 지정된 경로로 데이터를 파일 형태로 저장합니다. Overwrite의 경우, 동일한 파일 이름으로 저장하면 S3는 기존 파일을 자동으로 덮어씁니다. 그러나 이는 DuckDB에서 처리하는것이 아닌 S3 자체의 동작 방식입니다.
DuckDB에서 Overwrite 옵션이 없는 이유
DuckDB에 COPY 명령에서의 Overwrite 옵션이 없는 이유는 DuckDB가 파일 관리 작업보다는 데이터 처리 및 저장 작업에 집중하기 때문입니다.
보다 자세하게 설명하면,
-
파일 시스템 관리의 비효율성 : 파일 삭제나 덮어쓰기를 DuckDB 내에서 처리하려면 추가적인 API 호출과 복잡성이 필요한데, DuckDB는 임베디드 데이터베이스로 설계되어 파일 시스템을 관리하는 데 최적화되지 않았다고 합니다.
-
책임 분리 : DuckDB는 데이터베이스 엔진의 역할(데이터 처리 및 저장)에 집중하며, 파일 관리는 사용자나 외부 도구에 맡기도록 설계되어 있다고 합니다.
이러한 이유들 때문에 Overwrite 기능을 아래 예시 코드처럼 직접 구현해야 합니다.
def delete_s3_files_in_path(bucket: str, prefix: str):
s3_client = boto3.client("s3")
response = s3_client.list_objects_v2(Bucket=bucket, Prefix=prefix)
if "Contents" in response:
for obj in response["Contents"]:
s3_client.delete_object(Bucket=bucket, Key=obj["Key"])3. S3에서 Raw Data 조회 및 테이블 생성
이전에 저장된 파일 정리까지 진행되었다면 DuckDB를 통해 S3의 지정된 Partition에 접근해 파일들을 조회하고 테이블을 생성해야 되는데 아래 예시 코드처럼 간단하게 구현할 수 있습니다.
# 접근할 S3 Path 생성
raw_data_path = f"s3://test-datalake/raw-data/instagram/utc_time={utc_time}/*.json"
# 지정된 S3 Path에 접근해서 JSON 데이터 조회 및 테이블 생성
conn.execute(
"""
CREATE TABLE influencers AS
SELECT * FROM read_json_auto(?)
""",
[raw_data_path],
)#3 DuckDB를 통한 Cleansing 및 S3에 Cleansed-data 저장
1. 데이터 Cleansing 및 S3에 데이터 저장
아래 예시 코드처럼 DuckDB SQL을 통해 정해진 Schema에 맞게 Cleansing 후 Mapping 진행
user_s3_path = f"s3://test-datalake/cleansed-data/instagram/user/utc_time={utc_time}/{current_timestamp}.parquet"
# S3에서 조회한 JSON 데이터(계정 데이터) Cleansing 및 Cleansed Data S3에 다시 Parqeut으로 저장
conn.execute(
f"""
COPY(
SELECT
user.followed_by.count AS follower_count,
user.follow.count AS following_count,
user.full_name AS nickname,
user.profile_pic_url AS profile_image_url,
user.username AS username,
user.timeline_media.count AS media_count,
CAST(EPOCH(utc_snapshot_time ::TIMESTAMP) AS BIGINT) AS scraped_at_utc, -- UTC 현재 시간 추가
FROM influencers
)
TO '{user_s3_path}' (FORMAT 'parquet', COMPRESSION 'zstd');
"""
)
# 리소스를 효율적으로 관리하기 위해 connection 종료
conn.close()Cleansed Data는 바로 S3에 원하는 타입(Parquet)으로 저장이 가능합니다. Connection을 종료해 주지 않고 유지하면 불필요한 메모리와 시스템 리소스를 차지할 수 있기 때문에 리소스를 효율적으로 관리하기 위해 작업 종료 후 Connection은 종료해 주는 게 좋습니다.
2. 다양한 DuckDB COPY 옵션들
DuckDB COPY 명령어를 통해 데이터를 저장할때 지정할 수 있는 옵션들이 몇 가지 있는데 간략하게 소개하겠습니다.
-
FORMAT : 데이터를 저장하거나 읽을 때 사용할 파일 포맷을 지정합니다.
-
csv
-
parquet
-
json
-
arrow
-
orc
-
-
COMPRESSION : 데이터를 저장할 때 사용할 압축 방식을 지정합니다. 지원되는 압축 방식은 포맷에 따라 다릅니다.
-
Parquet:
-
zstd (기본값)
-
snappy
-
gzip
-
uncompressed (압축 없음)
-
-
CSV/JSON: 압축 옵션 없음.
-
-
ROW_GROUP_SIZE : Parquet 형식으로 저장할 때 Row Group의 크기를 지정하는 데 사용됩니다. Row Group은 Parquet 파일의 내부 구조에서 데이터를 물리적으로 저장하는 단위입니다.
-
기본값: 128MB
-
앞으로의 계획
이번 데이터 파이프라인 구축은 빠른 시간 안에 아키텍처 설계부터 실제 구축까지 진행했기 때문에, 대규모 데이터셋에 대한 테스트는 아직 진행 중입니다. 테스트가 완료되면, Cleansed Data를 빠르게 분석할 수 있는 분석 파이프라인까지 추가로 구축할 계획입니다.
저희 데이터 팀은 SNS 데이터를 효율적으로 수집, 가공, 분석할 수 있는 데이터 파이프라인을 통해 데이터 팀뿐만 아니라 다양한 내부 사용자들이 데이터를 쉽고 효율적으로 활용할 수 있는 환경을 만들고자 합니다. 또한, 국내뿐만 아니라 동남아시아, 북미 등 전 세계 SNS 데이터를 피처링 플랫폼을 통해 확인할 수 있는 환경을 구축하는 것이 목표입니다.
마무리
이번 DuckDB 도입을 통해 단순히 Data Cleansing에 그치지 않고, 데이터를 어떻게 잘 수집, 가공, 분석할지 고민하며 데이터 파이프라인을 설계하고 구축하는 과정을 경험할 수 있었습니다. 이러한 과정을 통해 여러 가지 경험과 다양한 인사이트를 얻게 되었고, 앞으로도 이를 바탕으로 더 나은 데이터 환경을 만들어 나갈 계획입니다.
DuckDB 도입을 고민하시는 분들에게 이 글이 작은 도움이 되었기를 바랍니다.